Subscribe to our newsletter
Thanks you for subscription!
Oops! Something went wrong while submitting the form.


This is part 1 of a 3 part blog series, read part 2 here
Enterprises are pushing forward with AI, but too often apply an ML mindset. The result is fragmented deployments, rising costs, and governance gaps. AI inference is not ML at scale, it requires a new operational model: InferenceOps.
In this blog, I’ll outline why the ML playbook once made sense, why it fails in the age of AI, how leading enterprises are adapting, and what a better operating model - InferenceOps - looks like.
The "ML playbook" refers to the common pattern where platform teams provided basic tooling and infrastructure for training and deployment, while individual use case teams used that tooling to train, deploy, inference, and manage their own models end-to-end. This playbook worked well for a few reasons:
Given these characteristics of ML inference, it made sense for inference to be done by the use case teams. Decentralisation of inference was logical, and platform teams simply needed to provide the tools to do it.
AI Inference is fundamentally different from ML Inference, and the decentralised inference playbook breaks down. Why?

Enter InferenceOps: the new function every enterprise adopting self-hosted or multi-provider AI will need to establish within their platform team. InferenceOps is a central capability responsible for delivering scalable, reliable, and governed AI APIs to downstream use case teams.
This setup lets use case teams innovate freely, while the InferenceOps team ensures efficient GPU utilization, consistently high uptime, and organization-wide governance. It’s a model already proven by Tier-1 banks and leading tech companies, which have converged on centralized inference platforms that expose APIs to their development teams.
The benefits to the enterprise of adopting this method of running AI inference is significant:
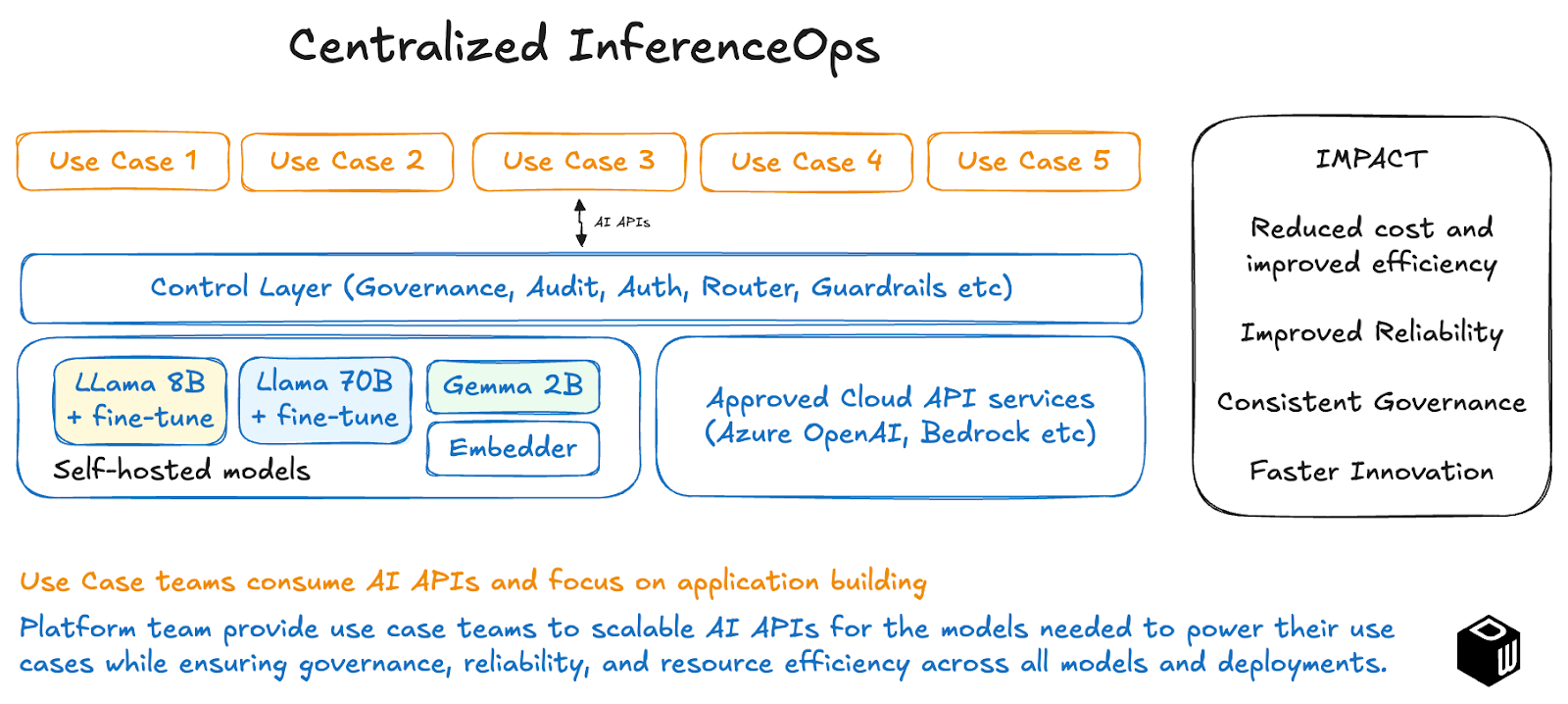
In ML, inference was an afterthought. In AI, inference is the bottleneck. Enterprises that maintain the decentralised MLOps-inspired playbook will overspend and underdeliver. Those that invest in centralized InferenceOps now will build the backbone for sustainable, enterprise-wide AI adoption.
Read the next part of the blog series here where I explain more about what this InferenceOps function will look like and be responsible for.


Teams use Doubleword to run low-cost, large-scale inference pipelines for async jobs.
Free credits available to get started.
